Proposal
Team Super Beast Warrior(SBW)
Batch-based Clickstream Analytics Platform
1. Executive Summary
This project aims to design and implement a Batch-based Clickstream Analytics Platform for a computer and accessories e-commerce website (The website’s frontend integrates a lightweight JavaScript SDK that sends user activity data (clicks, views, searches) to the backend API) using AWS Cloud Services. The system collects user interaction data (such as clicks, searches, and page visits) from the website and stores it in Amazon S3 as raw logs. Every hour, Amazon EventBridge triggers AWS Lambda functions to process and transform the data before loading it into a data warehouse hosted on Amazon EC2.
The processed data is visualized through R Shiny dashboards, providing store owners with business insights such as customer behavior patterns, product popularity, and website engagement trends.
This architecture focuses on batch analytics, ETL pipelines, and business intelligence while ensuring security, scalability, and cost efficiency by leveraging AWS managed services.
2. Problem Statement
What’s the Problem?
E-commerce websites generate a large volume of clickstream data—including product views, cart actions, and search activities—that contain valuable business insights.
However, small and medium-sized stores often lack the infrastructure and expertise to collect, process, and analyze this data effectively.
As a result, they face difficulties in:
- Understanding customer purchasing behavior
- Identifying top-performing products
- Optimizing marketing campaigns and website performance
- Making data-driven inventory and pricing decisions
The Solution
This project introduces an AWS-based batch clickstream analytics system that automatically collects user interaction data from the website every hour, processes it through serverless functions, and stores it in a central data warehouse on Amazon EC2.
The results are visualized using R Shiny dashboards, enabling store owners to gain actionable insights into customer behavior and improve overall business performance.
Benefits and Return on Investment
- Data-driven decision making: Discover customer preferences, popular products, and shopping trends.
- Scalable and modular design: Easily extendable to handle more users or additional data sources.
- Cost-efficient batch processing: Reduces continuous compute costs by operating on a scheduled, hourly basis.
- Business insight enablement: Empowers store owners to optimize sales strategies and improve revenue using evidence-based analytics.
3. Solution Architecture
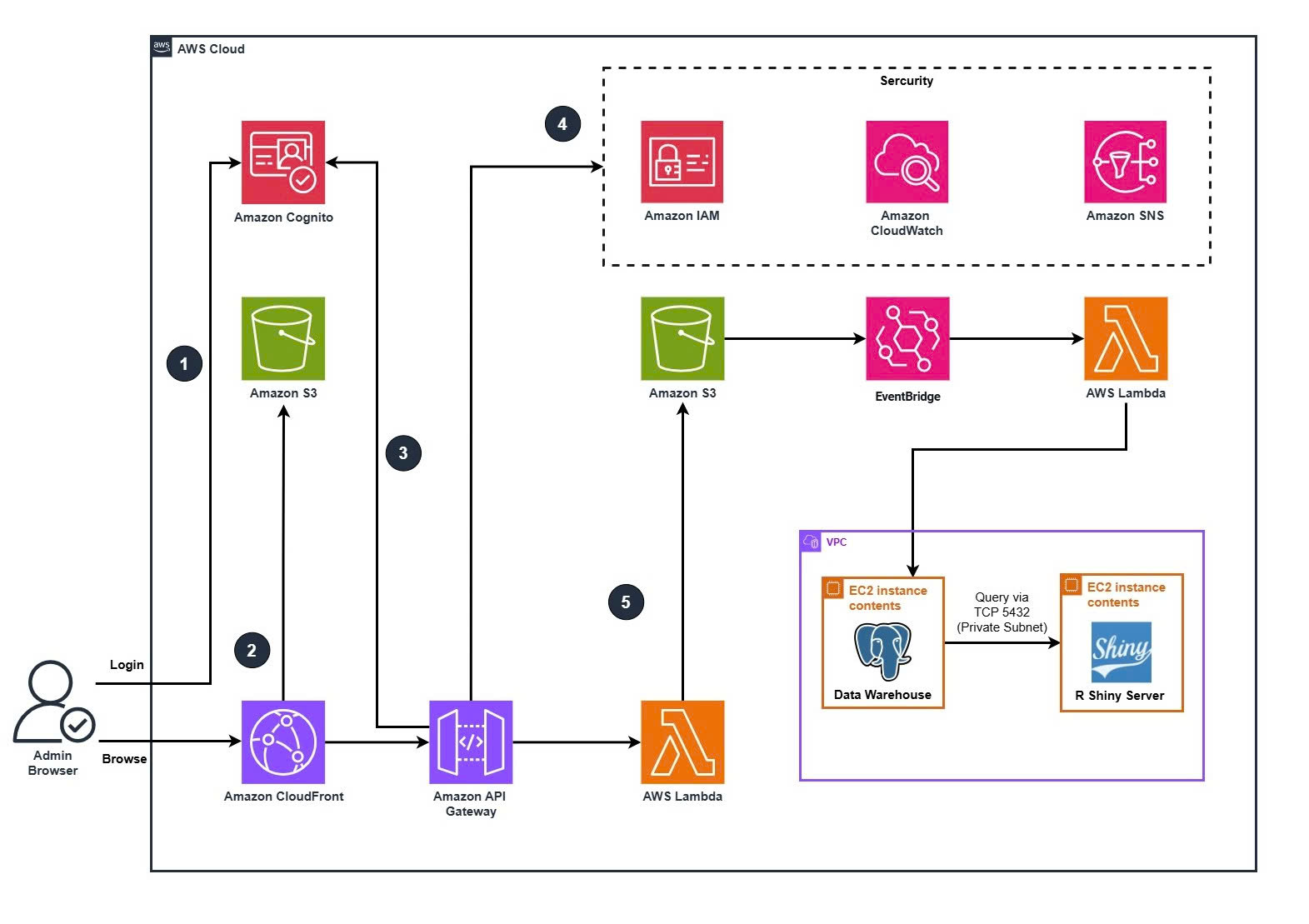
AWS Services Used
- Amazon Cognito: Handles user authentication and authorization for both administrators and website customers, ensuring secure access to the e-commerce platform.
- Amazon S3: Acts as a centralized data storage layer — hosting the static website front-end and storing raw clickstream logs collected from user interactions. It also temporarily holds batch files before they are processed and transferred to the data warehouse.
- Amazon CloudFront: Distributes static website content globally with low latency, improving user experience and caching resources close to customers.
- Amazon API Gateway: Serves as the main entry point for incoming API calls from the website, enabling secure data submission (such as clickstream or browsing activity) into AWS.
- AWS Lambda: Executes serverless functions to preprocess and organize clickstream data uploaded to S3. It also handles scheduled data transformation jobs triggered by EventBridge before loading them into the data warehouse.
- Amazon EventBridge: Schedules and orchestrates batch workflows — for example, triggering Lambda functions every hour to process and move clickstream data from S3 into the EC2 data warehouse.
- Amazon EC2 (Data Warehouse): Acts as the data warehouse environment, running PostgreSQL or another relational database for batch analytics, trend analysis, and business reporting. Both instances are deployed inside a VPC private subnet for network isolation and security
- R Shiny (on EC2): Hosts interactive dashboards that visualize batch-processed insights, helping the business explore customer behavior, popular products, and sales opportunities.
- AWS IAM: Manages access permissions and policies to ensure that only authorized users and AWS components can interact with data and services.
- Amazon CloudWatch: Collects and monitors metrics, logs, and scheduled job statuses from Lambda and EC2 to maintain system reliability and performance visibility.
- Amazon SNS: Sends notifications or alerts when batch jobs complete, fail, or encounter errors, ensuring timely operational awareness.
4. Technical Implementation
End-to-end data flow
- Auth (Cognito).
- Browser authenticates with Amazon Cognito (Hosted UI or JS SDK).
- ID token (JWT) is stored in memory; SDK attaches
Authorization: Bearer <JWT>for API calls.
- Static web (CloudFront + S3).
- SPA/assets hosted on S3; CloudFront in front with OAC, gzip/brotli, HTTP/2, WAF managed rules.
- The page loads a tiny analytics SDK that collects events and sends to API Gateway (below).
- Event ingest (API Gateway).
POST /v1/events(HTTP API). CORS locked to site origin; JWT authorizer validates Cognito token (or API key for anon flows).- Requests forwarded to Lambda.
- Security & Ops.
- IAM least-privilege for every component.
- CloudWatch logs/metrics/alarms on API 5xx, Lambda errors, throttles, Shiny health.
- SNS notifies on alarms & DLQ growth.
- Processing & storage (Lambda → S3 batch buffer → EventBridge → Lambda(ETL) → PostgreSQL on EC2 (data warehouse) → Shiny).
- Ingest Lambda validates/enriches events then append-writes NDJSON objects into S3 (partitioned by date/hour).
- EventBridge (cron) triggers an ETL Lambda (batch) on a fixed cadence (e.g., every 60 minutes).
- ETL Lambda reads a slice of S3 partitions, deduplicates, transforms, and upserts into PostgreSQL on EC2 (VPC access).
- R Shiny Server (on EC2) reads curated tables and renders dashboards for admins.
Data Contracts & Governance
Event JSON (ingest)
{
"event_id": "uuid-v4",
"ts": "2025-10-18T12:34:56.789Z",
"event_type": "view|click|search|add_to_cart|checkout|purchase",
"session_id": "uuid-v4",
"user_id": "cognito-sub-or-null",
"anonymous_id": "stable-anon-id",
"page_url": "https://site/p/123",
"referrer": "https://google.com",
"device": { "type": "mobile|desktop|tablet" },
"geo": { "country": "VN", "city": null },
"ecom":
{
"product_id": "sku-123",
"category": "Shoes",
"currency": "USD",
"price": 79.99,
"qty": 1,
},
"props": { "search_query": "running shoes" },
}
- PII: never send name/email/phone; any optional identifier is hashed in Lambda.
- Behaviour: generate anonymous_id once, maintain session_id (roll after 30 min idle), send via navigator.sendBeacon with fetch retry fallback; optional offline buffer via IndexedDB.
S3 raw layout & retention
- Bucket:
s3://clickstream-raw/ - Object format: NDJSON, optionally GZIP.
- Partitioning:
year=YYYY/month=MM/day=DD/hour=HH/ → events-<uuid>.ndjson.gz - Optional manifest per batch: processed watermark, object list, record counts, hash.
- Lifecycle: raw → (30 days Standard/IA) → (365+ days Glacier/Flex).
- Idempotency: maintain a compact staging table in PostgreSQL (or a small S3 key-value manifest) to track last processed object/batch and prevent double-load.
Frontend SDK (Static site on S3 + CloudFront)
Instrumentation
- Tiny JS snippet loaded site-wide (defer).
- Generates
anonymous_idonce and keepssession_idinlocalStorage; session rolls after 30 minutes of inactivity. - Sends events via navigator.sendBeacon; fallback to
fetchwith retry & jitter.
Auth context
- If user signs in with Cognito, include
user_id = idToken.subto enable logged-in funnels.
Offline durability
- Optional Service Worker queue: when offline, buffer events in IndexedDB and flush on reconnect.
Ingestion API (API Gateway → Lambda)
API Gateway (HTTP API)
- Route:
POST /v1/events. - JWT authorizer (Cognito user pool). For anonymous pre-login events, use an API key usage-plan with strict rate limits.
- WAF: AWS Managed Core + Bot Control; block non-site origins via strict CORS.
Lambda (Node.js or Python)
- Validate against JSON Schema (ajv/pydantic).
- Idempotency: recent
event_idcache in memory (short TTL) + batch-level dedupe during ETL. - Enrichment: derive date/hour, parse UA, infer country from
CloudFront-Viewer-Countryif present. - Persist: PutObject to S3 path
.../year=YYYY/month=MM/day=DD/hour=HH/.... - Failure path: publish to SQS DLQ; alarm via SNS if DLQ depth > 0.
Batch Buffer (S3)
- Purpose: cheap, durable buffer for batch analytics.
- Write pattern: small per-request objects or micro-batches (e.g., 1–5 MB each) with GZIP. Optional compactor merges into ≥64MB files for efficient reads.
- Read pattern: ETL Lambda scans only new partitions/objects since the last watermark.
- Schema-on-read: ETL applies schema, handles late-arriving data by reprocessing a small sliding window (e.g., last 2 hours) to correct sessions.
EC2 “data warehouse” node
Purpose: run ETL + host the curated analytical store that Shiny queries. Two choices:
- Postgres on EC2 (recommended if team prefers SQL/window functions)
- Instance: t3.small/t4g.small; gp3 50–100GB.
- Schema:
fact_events,fact_sessions,dim_date,dim_product. - Security: within VPC private subnet; access via ALB/SSM Session Manager; automated daily snapshots to S3
- ETL (Lambda, batch via EventBridge cron):
- Trigger: rate(5 minutes) / cron(…) depending on cost & freshness.
- Steps: list new S3 objects → read → validate/dedupe → transform (flatten nested JSON, cast types, add ingest_date, session_window_start/end) → upsert into Postgres using COPY to temp tables + merge, hoặc batched INSERT … ON CONFLICT.
- Networking: Lambda attached to VPC private subnets to reach EC2 Postgres security group.
R Shiny Server on EC2 (admin analytics)
Server
- EC2 (t3.small/t4g.small) with: R 4.4+, Shiny Server (open-source), Nginx reverse proxy, TLS via ACM/ALB or Let’s Encrypt.
- IAM instance profile (no static keys). Security group allows HTTPS from office/VPN or Cognito-gated admin site.
App (packages)
shiny,shinydashboard/bslib,plotly,DT,dplyr,DBI+RPostgresorduckdb,lubridate.- If querying DynamoDB directly for small cards, use
paws.dynamodb(optional).
Dashboards
- Traffic & Engagement: DAU/MAU, sessions, avg pages, bounce proxy.
- Funnels: view→add_to_cart→checkout→purchase with stage conversion & drop-off.
- Product Performance: views, CTR, ATC rate, revenue by product/category.
- Acquisition: referrer, campaign, device, country.
- Reliability: Lambda error rate, DLQ depth, ETL lag, data freshness.
Caching
- Query results cached in-process (reactive values) or materialized by ETL; cache keys by date range and filters
Security baseline
IAM
- Ingest Lambda: s3:PutObject to raw bucket (scoped to prefix), s3:ListBucket on needed prefixes.
- ETL Lambda: s3:GetObject/ListBucket on raw prefixes; permission to fetch secrets from SSM Parameter Store; no broad S3 access.
- EC2 roles: read/write only to its own DB/volumes; optional read to S3 for backups.
- Shiny EC2: no write to S3 raw; read-only to Postgres as needed
Network
- Place EC2 in private subnets; public access through ALB (HTTPS 443).
- Lambda for ETL joins the VPC to reach Postgres; SG rules least-priv (Postgres port from ETL SG only).
- No wide 0.0.0.0/0 to DB ports.
Data
- Encrypt EBS (KMS), S3 server-side encryption, RDS/PG TLS, secrets in SSM Parameter Store.
- No PII in events; retention: raw S3 90–365 days (lifecycle), curated Postgres per business policy
Observability & alerting
CloudWatch metrics/alarms
- API Gateway 5xx/latency, Lambda (ingest) errors/throttles, S3 PutObject failures, EventBridge schedule success rate, ETL duration/lag, DLQ depth, Shiny health check
SNS topics: on-call email/SMS/Slack webhook.
Structured logs: JSON logs from Lambda & ETL (request_id, event_type, status, ms, error_code).
Watermark tracking: custom metric “DW Freshness (minutes since last successful upsert)”.
Cost Controls (stay near Free/low tier)
- Use HTTP API (cheaper), minimal Lambda memory (256–512MB), compress requests.
- Batch over realtime: S3 as buffer eliminates DynamoDB write/read costs.
- S3 lifecycle: Standard → Standard-IA/Intelligent-Tiering → Glacier for older raw; enable GZIP to cut storage/transfer.
- Tune ETL cadence (e.g., 15–60 min) and process only new objects; compact small files into bigger chunks to reduce read I/O.
- Single small EC2 for Shiny + DW at start; scale vertically or split later.
- AWS Budgets with SNS alerts (actual & forecast).
Deliverables
- Analytics SDK (TypeScript) with sessionization + beacon + optional offline queue.
- API/Lambda (ingest) with validation, enrichment, idempotency hints, DLQ.
- S3 raw bucket spec (prefixing/partitioning, compression, lifecycle) + optional compactor.
- ETL Lambda (batch) + EventBridge cron + watermarking + upsert strategy to PostgreSQL.
- PostgreSQL schema (fact_events, fact_sessions, dims) + indexes + vacuum/maintenance plan.
- R Shiny dashboard app (5 modules) + Nginx/ALB TLS setup.
- Runbook: alarms, on-call, backups, disaster recovery, freshness SLO, cost guardrails
5. Timeline & Milestones
Project Timeline
Month 1 – Learning & Preparation
Study a wide range of AWS services including compute, storage, analytics, and security. Understand key concepts of cloud architecture, data pipelines, and serverless computing. Conduct team meetings to align project goals and assign responsibilities.
Month 2 – Architecture Design & Prototyping
Design the overall project architecture and define data flow between components. Set up initial AWS resources such as S3, Lambda, API Gateway, EventBridge, and EC2. Experiment with open-source tools for visualization and reporting. Test sample codes and validate the data ingestion and processing pipeline.
Month 3 – Implementation & Testing
Implement the full architecture based on the approved design. Integrate all AWS services and ensure system reliability. Conduct performance and functionality testing. Finalize documentation and prepare the project for presentation.
6. Budget Estimation
You can find the budget estimation on the AWS Pricing Calculator. Or you can download the Budget Estimation File.
Infrastructure Costs
AWS Services
Amazon Cognito(User Pools): 0.10 USD/monthly(1 Number of monthly active users (MAU), 1 Number of monthly active users (MAU) who sign in through SAML or OIDC federation)
Amazon S3
- 3 Standard:0.17 USD/monthly(6 GB, 1,000 PUT requests, 1,000 GET requests, 6 GB Data returned, 6 GB Data scanned)
- Data Transfer: 0.00 USD/monthly(Outbound: 6 TB, Inbound: 6 TB)
Amazon CloudFront(United States): 0.64 USD/monthly(6 GB Data transfer out to internet, 6 GB Data transfer out to origin, 10,000 requests Number of requests (HTTPS))
Amazon API Gateway(HTTP APIs): 0.01 USD/monthly(10,000 requests for HTTP API requests units)
Amazon Lambda(Service settings): 0.00 USD/monthly(1,000,000 requests, 512 MB)
Amazon CloudWatch(APIs): 0.03 USD/monthly(100 metrics GetMetricData, 1,000 metrics GetMetricWidgetImage, 1,000 requests API)
Amazon SNS(Service settings): 0.02 USD/monthly(1,000,000 requests, 100,000 calls HTTP/HTTPS Notifications, 1,000 calls EMAIL/EMAIL-JSON Notifications, 100,000,000 notifications QS Notifications, 100,000,000 deliveries Amazon Web Services Lambda, 100,000 notifications Amazon Kinesis Data Firehose)
Amazon EC2(EC2 specifications): 1.68 USD/monthly(1 instances, 730 Compute Savings Plans)
Amazon EventBridge: 0.00 USD/monthly(1,000,000 events(Number of AWS management events) EventBridge Event Bus - Ingestion)
Total: 2.65 USD/month, 31.8 USD/12 months
7. Risk Assessment
| Risk | Likelihood | Impact | Mitigation Strategy |
|---|---|---|---|
| High costs exceeding the estimated budget | Medium | High | Closely monitor and calculate all potential AWS expenses. Limit the use of high-cost AWS services and replace them with simpler, cost-effective alternatives that provide similar functionality. |
| Potential issues during data transfer or service integration between AWS components | Medium | Medium | Perform step-by-step validation before going live. Conduct early testing, use managed AWS services, and continuously monitor performance through Amazon CloudWatch. |
| Data collection or processing risks (e.g., excessive user interactions, network instability, missing or duplicated events) | High | Medium | Apply data validation, temporary buffering, and schema enforcement to ensure consistency. Use structured logging and alarms to detect and resolve ingestion errors. |
| Low or no user adoption of the analytics dashboard | Low | High | Conduct internal training sessions and leverage existing communication channels to raise awareness. Encourage adoption by showcasing the system’s practical benefits and actionable insights. |
8. Expected Outcomes
Understanding Customer Behavior and Journey
The system records the entire customer journey — including which pages users visit, which products they view, how long they stay, and where they exit the site.
By analyzing session duration, bounce rate, and navigation paths, businesses can evaluate user engagement and the overall experience.
This provides a reliable data foundation for improving website interface, optimizing page layout, and enhancing overall customer satisfaction.
Identifying Popular Products and Consumer Trends
Based on clickstream data collected and processed in AWS, the system identifies the most viewed and most purchased products.
Products that receive less attention are also tracked, enabling businesses to assess the effectiveness of product listings, adjust pricing or visuals, and plan inventory more effectively.
Furthermore, the system supports discovering shopping trends across time periods, regions, or device types — allowing for data-driven and timely business decisions.
Optimizing Marketing and Sales Strategies
Customer behavior data is transformed into business insights and presented through R Shiny dashboards.
With these analytical results, businesses can:
- Accurately define target customer segments for marketing efforts
- Customize advertising and promotional campaigns for specific product groups or demographics
- Evaluate the effectiveness of marketing initiatives through measurable engagement and conversion indicators
As a result, marketing and sales strategies become more evidence-based and precise, supporting better decision-making and improved business performance.